LLM Transformer Modeli Çalışma Prensipleri
LLM Transformer Modeli Çalışma Prensipleri
İçerik Son Güncelleme: 22 Mart 2026
Doğal dil işleme yetenekleri teknoloji dünyasında oyunun kurallarını yeniden yazıyor. İş süreçlerinden evdeki asistanlarımıza kadar hayatımıza giren büyük dil modelleri devasa bir değer üretiyor. Küresel endüstride bu pazarın milyarlarca dolar gelir potansiyeli taşıdığını görüyoruz. Bütün bu başarı hikayesinin arkasında büyük bir buluş var. Bu yazılım mucizesinin adı LLM Transformer modeli olarak geçiyor. Google şirketi araştırmacıları 2017 yılında bu modeli teknik dünyaya sundular. Bilgisayarların dili anlama ve metin yapma biçimini LLM Transformer modeli tamamen sıfırdan oluşturdu.
Peki ChatGPT ürünlerinin bu derece akıcı iyi cevaplar vermesini sağlayan modern altyapı nasıl işliyor? Yeni ufuklar açan teknolojik algoritmaları ayrıntılarıyla inceleyeceğiz. Bu geniş rehber yazımızda LLM Transformer modeli yeteneklerini, avantajlarını ve kullanım risklerini ele alıyoruz.
İçindekiler
- LLM Transformer Modeli Neden Devrim Yarattı?
- LLM Transformer Modeli Adım Adım Çalışma Mantığı
- Self-Attention (Öz-Dikkat) Mekanizması İşin Sırrı
- LLM Transformer Modeli ve RNN Karşılaştırması
- LLM Transformer Modeli Kısıtlamaları ve Sınırları
- Türkiye Ekosisteminde LLM Transformer Modeli Uyumluluğu
- 2026 Pazar Gelirleri ve Endüstri Vizyonu
- Sonuç
- FAQ
LLM Transformer Modeli Neden Devrim Yarattı?
Özetle (TL;DR): LLM Transformer modeli, metin verilerini sıralı okuyan eski nesil sistemlerin aksine verileri eş zamanlı ve paralel işler. Bu mucizevi hız sıçraması çok daha büyük metinlerin dakikalar içinde eğitilebilmesini ve günümüz yapay zekasının temelini atmasını sağlamıştır.
Kapsamlı yapay sinir ağlarının temelini LLM Transformer modeli güçlü mimarisi kuruyor. Araştırmacılar 2017 senesinde "Attention Is All You Need" adlı o tarihi makaleyi kamuoyuna yayınladılar. O devire kadar eski teknolojiler daima kelimeleri sıralı ve çok yavaş işliyordu. Ancak LLM Transformer modeli sadece dikkat mekanizmalarını kullanarak tüm işi anında çözdü.
Grand View Research raporlarına göre küresel büyük dil modelleri sektör değeri hızla artıyor. Bu özel sektörün 2026 yılında ortalama 10.5 milyar dolara ulaşmasını şiddetle bekliyoruz. Dev pazar büyümesinin en ateşleyici motorunu LLM Transformer modeli dinamikleri tetikliyor.
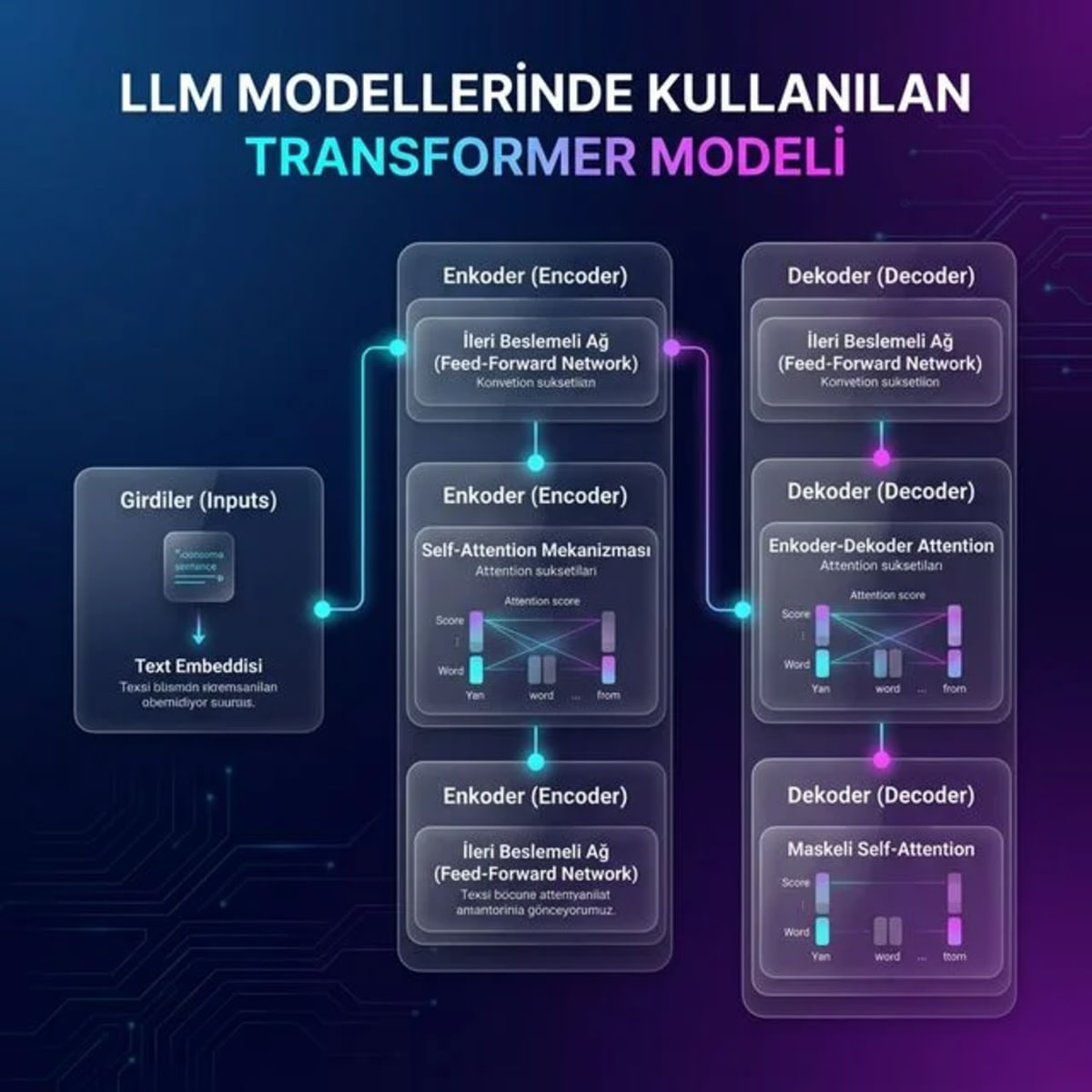
LLM Transformer Modeli Adım Adım Çalışma Mantığı
Mucizevi sonuçlar üreten algoritmanın arkasında sağlam matematiksel bir zemin var. Doğal dil kurallarını öğrenmesi için LLM Transformer modeli temel olarak dört kritik adımdan meydana gelir.
1. Tokenization ve Embedding İşlemi
Tokenization evresinde makine, kullanıcının girdiği kelimeleri küçük yapısal dilimlere mantıkla bölüyor. Sonra "Embedding" tekniği sahneye çıkıyor. Bölünen bu parça verilerini yüksek boyut uzayındaki bir sayı vektörüne anında çeviriyor. IBM mühendislerinin bilgi bankasında dediği gibi sistem, kavramları kelimelerle değil doğrudan matematiksel sayılarla okuyor.
2. Positional Encoding Aşaması
Paralel ve çoklu okuma yaptığımız için eş zamanlı yollanan veride sıra karışabilir. Yanlışları önlemek için algoritmaya kelimenin pozisyonunu anlatan ekstra vektör kodu yolluyoruz. İşte LLM Transformer modeli eklenen konumsal kodlamayı okuyor ve harf dizilimini mükemmel biçimde zihninde koruyor.
3. Encoder (Kodlayıcı) Görevi
Metin baştan uca burada süzgeçten geçiyor. LLM Transformer modeli orijinal mimaride kodlayıcı tarafını defalarca kez kullanıyor. Bu katmanlar cümlenin detaylı bağlamlarını alıyor ve diğerleriyle sentezliyor. Bütün girdileri çok zengin yoğun bilgi matrisine büyük oranla kusursuz programlıyor.
4. Decoder (Kod Çözücü) Finali
Beklediğimiz o akıcı mükemmel makale sonuçlarını doğrudan kod çözücü üretiyor. LLM Transformer modeli kodlayıcı kısımdan en zengin veriyi eksiksiz çekiyor. Kullanıcının ondan istediği asıl harika hedef yanıtı matematiksel formüllerle yazıyor.
Self-Attention (Öz-Dikkat) Mekanizması İşin Sırrı
Özetle (TL;DR): Öz-dikkat (Self-Attention) mekanizması, bir cümleyi okurken her kelimenin diğer tüm kelimelere ne kadar ilgili ve bağlı olduğunu puanlayan, NLP işlemlerinde hatayı neredeyse sıfıra indiren matematiksel bir işlemdir.
Gelenekselleşmiş yapılar daima cümlenin sadece son kelimesini daha önemli ve değerli görüyorlar. Ancak öz-dikkat devri LLM Transformer modeli içinde her kelimeyi diğeriyle yan yana puanlıyor. Böylece yazılım aynı bir profesyonel insan gibi metni kopmadan tam değerlendiriyor. Uzun bir eylem odaklı yapay zeka agentic ai skill dokümanını işlerken dikkati hiç sönmüyor.
Matematik algoritmalarında daima "Sorgu, Anahtar, Değer" kavram üçlüsünü kullanıyor. Her kelime "Ben kime daha çok odaklanmalıyım?" diye kendi kendine sorgu atıyor. Diğer kelimeler ona anında hızla yanıt vererek kendini tanımlıyor. Datacamp eğitimcilerine bakarsanız, Çok Başlı Dikkat sayesinde makine bu hesabı çok farklı kombinasyonlarla sürekli yapıyor.
LLM Transformer Modeli ve RNN Karşılaştırması
Özetle (TL;DR): RNN sadece ardışık veri işlerken LLM Transformer modeli paralel işleme yaparak hız devrimi sağlamıştır. RNN'de görülen başı unutma problemi (Vanishing Gradient) Transformer'da yoktur.
| Özellik Tablosu | RNN & LSTM Modelleri | LLM Transformer Modeli |
|---|---|---|
| İşlem Tipi | Sıralı Adım Adım (Çok Yavaş) | Paralel Eş Zamanlı (Aşırı Hızlı) |
| Hafıza (Bağlam) | Kısa kapasite ("Vanishing Gradient" hatası) | Bütün metni eş zamanlı bütünsel anlar |
| Kullanım Alanı | Küçük kelime ve cümle çevreleri | Milyarlarca parametre ile devasa RAG sistemleri |
RNN kelimeleri birer birer okurken cümlenin sonlarına gelince en başını hemen unutuyordu. Uzmanlar bu meşhur hafıza hatasına "vanishing gradient" yani sönümlenen bellek hatası diyor. Lakin LLM Transformer modeli paralel okuduğu için bininci kelime ile birinci kelime arasında şelale gibi harika muhteşem akıllı bağ kuruyor. Medium yazar makaleleri okuyan uzmanlar, metin anlama kısmında dev sektörün tartışılmaz yeni süper kahramanı tamamen LLM Transformer modeli gerçeğidir diyor.
LLM Transformer Modeli Kısıtlamaları ve Sınırları
Bir LLM Transformer modeli geliştirmenin faturası dudak uçuklatıyor. Milyar dolarlık donanımlar ekran kartları almanız şart oluyor. OpenAI gibi devlerin harcadığı eforu okursak, yeni dev GPT sürümlerini sıfırdan ilk andan tam hazır finale eğitmenin en az 100 milyon Amerikan dolar maliyet faturasını tuttuğunu herkes açıkça konuşuyor.
Diğer aşılması gereken teknik bariyer de halüsinasyon olarak sektöre yayılan yanlış yanıt uydurma tehlikesidir. Kısıtlı zayıf az içerikle hatalı beslenen LLM Transformer modeli zamanla kendinden emin tonda asılsız bolca sahte bilimsel cümleler kurar.
Türkiye Ekosisteminde LLM Transformer Modeli Uyumluluğu
Özetle (TL;DR): Türkiye pazarında siber güvenlik ve KVKK sebebiyle yerel firmalar açık bulut platformlarından ziyade kendi bünyelerinde barındırdıkları "On-premise" LLM teknolojilerini tercih etmeye odaklanmıştır.
Webrazzi araştırma haber siteleri e-ticaret sitelerinin yarattığı LLM Transformer modeli örnekleri oldukça sık manşete taşıyor. Finans markaları büyük dev bankacılık kurumsal yüksek altyapı işlerinde bankalara has özel ulusal yerli çözümler geliştiriyor.
Aynen tam da bu önemli noktada mahremiyeti KVKK Madde 5 kurallarına tam denk sıfır zayıf uyumlu harika On-premise izolasyonlu kapalı içi kurum dev modellerini herkes daha ciddi alıyor. İzole tamamen kopuk ulusal kapalı kendi mimarisindeki LLM Transformer modeli hizmetini dışa hiçbir veri damlası sızdırmadan kendi merkez server yapısında kullanıyor. Türkiye kendi LLM yazılımlarını üretmeye odaklandı.
2026 Pazar Gelirleri ve Endüstri Vizyonu
Gelecek vizyonunda LLM Transformer modeli her veri tipi ile ortak çalışıp iş akışlarını otomatik ve multimedya ağırlıklı yönetecek. Yüksek otonom zeka iş sürekliliğini teminat altına alacak.
"Büyük dil modellerinden elde edilen verimlilik olağanüstü ve şaşırtıcı seviyelerde ilerliyor. Önümüzdeki beş ila on yıl içinde sadece yapay zeka sektöründe küresel olarak 10 ila 12 trilyon dolar arasında tarihi bir gelir bekliyoruz."
— Cathie Wood, Ark Invest CEO'su
Otomasyon yapan bir kurum her alanda mali bütçeleri daraltıyor. Otonom akıllı teknoloji pazar şirket robot çalışanlar tüm yoran angarya görevlerini makine saniyelerinde aniden bitiriyor.
Sonuç
Doğal dil işlemede yeni ufuklar sunan LLM Transformer modeli modern sanayi tarihin en süper buluşu oldu. Modellerin getirdiği teknik limitler, yüksek enerji ihtiyaçları ya da KVKK özel güven endişeleri her an konuşuluyor ancak iyileştirmeler kesilmeden anlık süreğen aralıksız hızla geliyor.
Sizler de kendi firmalarınızı bu geleceğe kusursuz oturtmayı arzu ediyorsanız ekiplerinizle görüşmelisiniz. Firma işleyiş haritası rotanızı duraksamadan hemen tasarlayın. Sistem size çok paha biçecek. Teknoloji geleceğin tamamen bizzat ta kendisidir.
FAQ
LLM Transformer Modeli Nedir?
Bu mimari eski dönem ürünlerde görünen yavaş metin işleme hantallığını paralel eş zaman değerlendirme hızı ile silip süpürerek tamamen ortadan kaldıran harika modern teknolojik yazılım dev zeka bulutu mimarisidir.
Self-Attention (Öz-Dikkat) Mekanizması Nasıl Çalışır?
Uzun cümlelerde uzak kelime grupları arasında geçen semantik sağlam ilişkilere hızlıca bir puan katarak değerlendirir. Böylelikle cümlenin baş öznesinin ana fiiline olan asıl mantıksal gerçek anlam ilişkisini makul ölçülerde iyi hesaplar.
Büyük Dil Modelleri Neden LLM Transformer Modeli Seçer?
Geleneksel algoritmalara kıyasla çok çok fersah fazlasıyla olağanüstü hıza ivmeye çıkaran çok paralelli bir okuma sistem modeli sunar. Trilyon dev parametreli o verilerde dahi anlamsal çökme olmayıp istikrarlı kalır.
KVKK Standartlarına Göre LLM Kullanımı Nasıl Kurgulanır?
Hassas şirket marka değer sırlarını tam güvende sürekli tutmak isteyen idari yönetici ekipleri dış buluta veri asla vermez. Kurumlar kendi korumalı sunucularında on-premise kurulumu kapalı iç hat yapıp KVKK madde uyumunu sağlar.
LLM Transformer Modeli İle RNN Arasındaki Fark Nedir?
RNN adlı eski yavaş sistem kelimeleri teker teker baştan sona okur ve yolda tökezler. Fakat akıllı olan yeni nesil mimari LLM Transformer modeli aynı anda paralelde tüm metni anında algılar.