Gemini Embedding 2 Teknik İnceleme: Geliştiriciler İçin RAG Rehberi
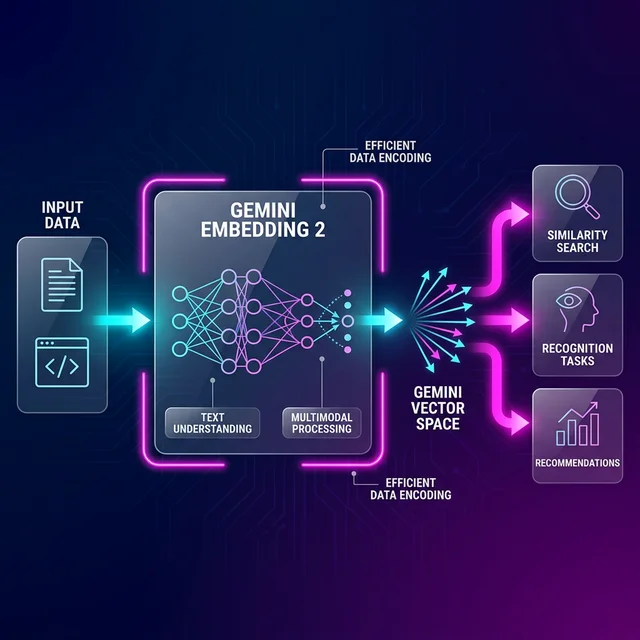
Yapay zeka modelleri artık sadece metni anlamıyor veya çözmüyor, dönemi tamamen değiştirdi. Google yakın zamanda Gemini Embedding 2 modelini duyurdu. 100'den fazla dil desteği barındıran bu teknoloji; metin, görsel, video, ses ve PDF belgelerini tek bir matematiksel uzayda (unified embedding space) başarıyla harmanlıyor. Geliştiriciler, bu model ile gerçek anlamda ezber bozan güçlü bir yetenek setine kavuşuyor.
Hazırladığımız bu detaylı Gemini Embedding 2 teknik inceleme dosyasında, modelin sadece yüzeysel özelliklerini listelemeyeceğiz. Arka planda çalışan Matryoshka Representation Learning (MRL) teknolojisini inceleyeceğiz, MTEB performans metriklerini değerlendireceğiz ve RAG (Retrieval-Augmented Generation) projelerinize hızlıca nasıl entegre edebileceğinizi adım adım açıklayacağız. Sistemin sınırlarını zorlarken, Mursel Net blog yazıları ile güncel kalın, en iyi pratikleri (best practices) uygulayarak projenizi başarıya taşımanıza yardımcı olacak.
İçindekiler
- Gemini Embedding 2 Rakiplerinden Farkı Nedir?
- Teknik Özellikler ve Kapasite Sınırları
- Matryoshka Representation Learning (MRL) İle Verimlilik
- RAG (Retrieval-Augmented Generation) Süreçlerinde Gemini Embedding 2
- Adım Adım RAG Entegrasyon Rehberi
- Türkçe Dil Performansı ve Özel MTEB Sonuçları
- Sık Yapılan Hatalar ve En İyi Uygulamalar (Best Practices)
- Sonuç Değerlendirmesi
- Sık Sorulan Sorular
Gemini Embedding 2 Rakiplerinden Farkı Nedir?
Özet Yanıt: Gemini Embedding 2, metin, görsel, PDF dosyaları, ses kayıtları ve videoyu aynı anda tek bir uzayda işleyebilen "gerçek anlamda çok modlu" (natively multimodal) bir modeldir. Geleneksel modellerin (örn. OpenAI text-embedding-3) aksine her veri tipi için ayrı ağ gerektirmez.
Piyasadaki pek çok embedding (gömme) modeli, tarihsel olarak sadece metin işlemlerine odaklanır. OpenAI'ın popüler text-embedding-3 ailesi de dahil olmak üzere çoğu güçlü model, farklı veri tipleri için ayrı işlem yetenekleri talep eder. Projede bir metin analizi gerekiyorsa ayrı, görsel arama gerekiyorsa ayrı ağlar kullanırsınız. Ancak Gemini Embedding 2, gerçek anlamda "natively multimodal" (doğal çok modlu) ilk yerel gömme modelidir.
Sistem, bir PDF dökümanındaki metni rahatlıkla okur. Buna ek olarak, eğitim videosundaki (MP4) 120 saniyelik bir kesiti veya sunumdaki 6 ayrı grafiği (PNG) alıp aynı anlamsal uzayda konumlandırabilirsiniz. Google verilerine göre bu yenilik, veri işleme hatlarınızı (pipeline) radikal bir şekilde basitleştirir.
Örnek bir kullanım senaryosu düşünün: "Dünkü şirket toplantısında gösterilen son çeyrek mavi tablolu slayt" şeklinde metinsel bir arama sorgusu yazıyorsunuz. Sistem, bu sorguyla veritabanındaki doğrudan ilgili video kesitini saniyeler içinde karşınıza çıkarır. Aramaları artık eski usül anahtar kelimelerle değil, bağlamın ta kendisiyle yürütürsünüz. Çapraz arama (cross-modal retrieval) denilen bu kavramla, teknik incelememiz bağlamında projelere muazzam bir çeviklik kazandırıyoruz. Mursel Net'teki diğer SEO araçlarına da gözatın.
Teknik Özellikler ve Kapasite Sınırları
Özet Yanıt: Gemini Embedding 2, tek istekte 8.192 metin token'ını, aynı anda 6 adet görsel/PDF sayfasını, 120 saniyelik videoyu veya 80 saniyelik ses dosyasını okuyabilir. Ayrıca hedefe yönelik benzerlik araması için Task Instructions (Görev Tanımlamaları) desteği sunar.
Gemini Embedding 2 modeli, geliştiricilerin devasa veri setleriyle sorunsuzca çalışabilmesi adına ekstra genişletilmiş bağlam pencereleri (context windows) sunar. Yüksek işlem kapasiteleri geliştirme sürecinizi ciddi oranda rahatlatır:
| Veri Tipi | Maksimum Kapasite (Tek İstek İçin) | Ek Özellikler |
|---|---|---|
| Metin | 8.192 Token | Uzun formlu belgeler için ideal |
| Görsel & PDF | 6 Adet/Sayfa | Dahili Optik Karakter Tanıma (OCR) içerir |
| Video | 120 Saniye | MP4 ve MOV formatları desteklenir |
| Ses | 80 Saniye | Transkript olmadan doğrudan vektörleştirme (MP3, WAV) |
Sistemin sunduğu harika bir diğer kritik özellik ise Görev Tanımlamaları (Task Instructions) desteğidir. Geliştiriciler, veriyi hangi amaca uygun gömdüklerini açıkça belirtebilirler. Örneğin, devasa bir RAG sistemi kuruyorsunuz. Arama sorguları için API'ye task:search result tanımı geçersiniz. Kod parçacıklarını indekslerken ise task:code retrieval parametresini belirtirsiniz. Bu basit kullanım hilesi, veritabanı eşleştirmelerinde benzerlik doğruluğunu inanılmaz ölçüde artırır.
Matryoshka Representation Learning (MRL) İle Verimlilik
Özet Yanıt: MRL teknolojisi, Gemini Embedding 2'nin 3072 boyutlu vektörlerinin sadece ilk elemanlarını koruyarak 768 veya 1536 boyuta güvenle kırpılmasını sağlar. Bu sayede doğruluk sadece %0.2 düşerken, veritabanı depolama maliyetlerinde %75'e varan tasarruf edilir.
Büyük dilli modeller (LLM) geliştirenlerin ortak sıkıntısı, devasa vektör boyutlarının yüksek depolama ve donanım hesaplama maliyetleri yaratmasıdır. Çoğu yüksek performanslı güncel model, en az 3072 veya çok daha yüksek boyutlu (dimensions) karmaşık vektörler üretir. Gemini Embedding 2 ekibi, Matryoshka Representation Learning (MRL) isimli harika bir algoritmik teknik kullanarak bu kronik sorunu zarifçe çözer.
Rusların içiçe geçen geleneksel Matruşka bebeklerinden referans alan bu yaklaşım, vektörün en değerli anlamsal bilgilerini dizilimin ilk elemanlarında yoğunlaştırır. Google modeli varsayılan (default) ayar olarak 3.072 boyutlu çıktılar üretir. Ancak MRL mimarisi, geliştiricilere performanstan neredeyse hiç taviz vermeden bu boyutu direkt kod üzerinden 1.536 veya daha kompakt olan 768 seviyesine diledikleri gibi indirme (truncate) şansı tanır.
Google'ın paylaştığı resmi kıyaslama belgelerine (benchmark) göre, tam teşekküllü 2.048 boyutta 68.16 MTEB puanı başaran sistem, vektörleri 768 boyutuna düşürdüğünde dahi 67.99 puanlık olağanüstü bir doğruluğu sürdürür. Bu optimizasyon; popüler Pinecone, Weaviate, Qdrant veya açık kaynaklı ChromaDB gibi vektör veritabanlarında yüzde 75 oranlarına ulaşan devasa depolama tasarrufları sağlar. Google DeepMind araştırmacısı Aleksei Baevski bu durumu "Matryoshka Representation Learning, çoklu görev ağlarında kaynak tüketimini azaltırken doğruluğu koruyan bir devrimdir" şeklinde ifade etmektedir. Bulut faturası dostu projelere bu yolla imza atarsınız.
RAG (Retrieval-Augmented Generation) Süreçlerinde Gemini Embedding 2
Özet Yanıt: Gemini Embedding 2'nin "Aranmış Girişler" (Interleaved Input) desteği sayesinde, RAG mimarilerinde görselleri önce metne çevirmek (image captioning) zorunda kalmazsınız. Hem metni hem resmi eş zamanlı gönderip doğrudan semantik aramaya dahil edebilirsiniz.
Güncel, kapalı domain projelerde (kurumsal asistanlar gibi) RAG mimarileri altın standarttır. Geliştiriciler, devasa dil modellerine dış dünya kaynaklarından verifiye edilmiş bilgi enjekte ederek o meşhur "halüsinasyon" (uydurma) sorununu RAG sayesinde başarıyla bloke eder. Hazırladığımız Gemini Embedding 2 teknik inceleme dökümanı boyunca vurguladığımız "Aranmış Girişler" (Interleaved Input) desteği RAG dünyasında devrim niteliğindedir.
Klasik mimarilerde, PDF içindeki diyagramı veya bir grafiği veritabanına sokmadan hemen önce üçüncü parti bir LLM sisteminden destek almanız gerekirdi. Görsel açıklamasını yazdırmak (image captioning) zorundaydınız. Artık yeni Gemini API kullanarak bu ekstra adımları atlar, görsel veriyi dosya olarak olduğu gibi pipeline üzerinden API'ye doğal şekilde postalarsınız. Sistem aradaki doğal bağı kendisi hızlıca kurar.
Adım Adım RAG Entegrasyon Rehberi
Özet Yanıt: Başarılı bir RAG işleminin reçetesi 4 maddedir: 1) Verileri tek klasöre temizleyin, 2) Batch isteklerle gemini-embedding-2-preview modeline veriyi gönderin, 3) Dönen vektörleri pgvector veya ChromaDB'ye kaydedin, 4) k-NN araması ile sonuçları Gemini modellerine bağlayın.
- 1. Veri Boru Hattının (Pipeline) Hazırlığı: Projenizdeki karmaşık verileri (uzun metin parçaları, MP3 ses kayıtları, toplantı PNG görselleri) proje klasörünüzde hazırlayıp dikkatlice derleyin. Temizleme süreçlerini (preprocessing) önceden bitirin.
- 2. Chunking (Parçalama) & Embedding Çalıştırma: Python veya Node.js SDK paketleri kullanarak metin blokları ve görselleri tek seferde (batch) ilgili API uç noktasına doğrudan aktarın. Kesinlikle
gemini-embedding-2-previewmodel varyantını seçtiğinizden emin olun. Vektör çıktısını 1536 olarak kilitleyin ki hız ve maliyet limitlerinde optimizasyon sağlayasınız. - 3. Vektör Veritabanı Seçimi: Hızlı okuma kapasitesi sunan bir teknoloji belirleyin. Çıktı vektörlerini PostgreSQL altındaki güçlü pgvector modülüne veya ChromaDB platformuna kaydedebilirsiniz.
- 4. Retrieval (Geri Alma) Aşamasının Kurulumu: Son kullanıcı sistemi kullanarak doğal dilde bir soru sorduğunda, arka planda hızlıca bu sorguyu yeniden vektörleştirin. En yakın komşuluk aramalarını (k-NN) tetikleyerek veritabanınızdan en mantıklı sonuçları güvenle çekin. En nihayetinde çıkartığınız ham bağlam metinlerini Gemini 2.0 Flash veya Gemini 1.5 Pro sistemine ana komut (prompt) zinciri olarak iletirsiniz.
Türkçe Dil Performansı ve Özel MTEB Sonuçları
Özet Yanıt: Gemini Embedding 2, Türkçe haber ve hukuki belge analizlerinde %99,17'lik klasifikasyon doğruluğu göstermiştir. Yerel Türkçe BERT modellerine karşı kosinüs benzerliği alanında 0.97 puanla tartışmasız liderdir.
Küresel çapta üretim yapan veya farklı ülkelere yazılım ihracatı sağlayan takımlar için iyi çalışan çok dilli destek bir lüks değil, olmazsa olmaz bir mecburiyettir. Gemini Embedding 2 mimarisi, Massive Multilingual Text Embedding Benchmark (MMTEB) listelerini altüst ederek günümüzde 250'den fazla dilde aktif işlem yeteneği sunar. Bu bağlamda rakip sistemlerin açık ara önüne atlamayı başarır. Google Cloud belgeleri üzerinden detayları inceleyebilirsiniz.
Sadece Türkçe özelinde, haber külliyatlarında ve hukuki doküman taramalarında yapılan test analizlerinde, NLP modeli inanılmaz skorlar verdi. Sistem sınıflandırma görevleri sırasında tamı tamına %99,17 (F1-score) gibi hataya yer bırakmayan bir doğruluk derecesine tırmandı.
Model yarışında, bağımsız geliştiriciler tarafından uzun zaman zarfında eğitilen mevcut açık kaynaklı Türkçe BERT algoritmalarını dahi eledi. Türkçe kelime setindeki zor anlamsal arama ve kosinüs benzerliği testlerinde 0.91'e karşılık tam 0.97 gibi rakipsiz puanlık üstünlük kurdu. Türkçe kelimelerin sondan eklemeli yapısını harika kavrıyor. Yerli kullanım senaryolarında pazarın açık ara en sağlam yapı taşı olduğunu geliştirici camiasına tam anlamıyla kanıtladı. Gemini Embedding 2 teknik inceleme notlarımıza, Türkçe projelerde tereddüt etmeden sisteme güvenebileceğinizi kalın harflerle açıkça yazıyoruz.
Sık Yapılan Hatalar ve En İyi Uygulamalar (Best Practices)
Özet Yanıt: Doğru sonuç için eski 001 modelinden gelen verilerinizi re-embed yapmalı, API'ye task_type parametresini mutlaka girmeli ve MRL ile vektör boyutunu düşürdüğünüzde her zaman manuel "L2 Normalizasyon" uygulamalısınız.
Sektöre yeni sunulan gelişmiş bir modele hızlıca adapte olurken ya da RAG projelerinize sıfırdan start verirken bazen geliştiricileri yoran ciddi teknik bariyerler oluşur. Zaman kayıplarının önüne geçmek adına dikkate almanız gereken çok önemli hata önleme pratikleri mevcuttur.
- Model Kodları ve Sürüm Uyumsuzluğu: Geçmişte muhtemelen
gemini-embedding-001sürümlerini kullanarak harikulade çalışan veri gölünüzü yarattınız. Ne yazık ki, Google dokümanlarına göre eski ve yeni sürümlerin anlamsal harita vektör uzaylarında teknik olarak direkt eşleme yeteneği yoktur. Sistemler tamamen uyumsuzdur. Yani eskiyü çöpe atmalısınız. Başarı için tüm mevcut devasa veritabanını yeni ve güçlügemini-embedding-2-previewile sıfırdan kodlayarak en baştan gömmeniz (re-embed işlemi) mutlak suretle gerekir. - Görev Parametrelerinin (TaskType) Eklenmemesi: Standart API isteklerinde
task_typeisimli opsiyonel bir parametre yer alır. Çoğu geliştirici bunu önemsemez ve atlar. Boş parametre kullanımı, oldukça genel geçer, odaklanmamış ve hatalara gebe zayıf sonuçlar doğurur. Hedeften şaşmamak ve performansı uçurmak için proje ihtiyacına uygun olacak şekilde mutlak suretleRETRIEVAL_DOCUMENTveya aramalar özelindeRETRIEVAL_QUERYvaryantlarından uygununu dikkatlice ekleyin. - Küçültülen Vektör Normalizasyon İhlali: MRL algoritmasının avantajlarını kullanarak boyutu agresif bir şekilde küçültürseniz (örneğin sadece 768 yuvacık) elde ettiğiniz bu yepyeni vektörü üretim (production) veritabanına yazmadan tam bir an önce durun. Bu işlenmiş veriyi manuel bir şekilde L2 normalizasyon (L2 normalization) filtresinden kesinlikle geçirin. Normalizasyonu atlarsanız, algoritmik kosinüs benzerliği (cosine similarity) fonksiyon aramalarınız size ilgisiz ve kalitesiz sonuç kümeleri fırlatır.
Sonuç Değerlendirmesi
Yazıda aktardığımız bulgulara göre Gemini Embedding 2 sadece popüler veya geçici "bir metin vektör modeli" olmanın fazlasıyla ötesindedir. Geliştiricilerin yıllardır beklediği, karmaşık dosya boyutlarını aynı havuzda eritebilen yepyeni bir çoklu ortam veri haritalama altyapısıdır. Metinleri, yüzlerce MP4 videosunu, ses kayıtlarını ve resim dokümanlarını sorunsuzca okuyarak tek bir birleşik evrende kolaylıkla harmanlarsınız.
Ek olarak Matryoshka Temsil Öğrenimi optimizasyon algoritması kullanarak projedeki aylık yüksek donanım ve sunucu (bulut) faturası giderlerini dramatik şekilde hafifletebilirsiniz. Özellikle Türkçe dahil olmak üzere onlarca düşük kaynaklı dildeki rakipleri ezen üstün MTEB sonuç puanları; projelerinizi kesinlikle başarıya ulaştırır. Akıllı RAG sistemleri kodlamak yepyeni nesil çok ajanlı (multi-agent) sanal şirket asistanları üretmek isteyen yazılım mimarları için son derece stabil ve paha biçilemez bir temel kurar. Eskiyen dağınık altyapılarınızı güncelleyin ve kullanıcılarınıza inanılmaz derinlikte arama deneyimleri yaşatmak için zaman kaybetmeyin.
Sıkça Sorulan Sorular (FAQ)
Gemini Embedding 2 Hangi Veri Formatlarını Algılıyor?
Model tam kapasite çalışarak metin dosyalarını, standart görselleri (PNG, JPEG formatları), internet üzerindeki kısa videoları (MP4, MOV uzantıları) başarıyla ve hızlıca algılar. Ses içeriklerini (MP3, WAV) okuyabildiği gibi kurumsal PDF belgelerini de doğrudan platform içine alır ve destekler.
Matryoshka Algoritması (MRL) Veritabanı Giderlerini Nasıl Hafifletir?
Geliştiricilere sunulan MRL fonksiyonu, ana vektörlerin performans doğruluğu asla bozulmadan temel 3072 birimden çok daha kolay taşınan 1536 veya minimal 768 boyut seviyelerine kırpılmasını rahatça sağlar. Daha dar yapı sayesinde bulut hizmet sunucularına çok daha iyi yerleştiği için direkt olarak veritabanı gider kalemlerinizi harika şekilde optimize eder.
Sistemin Metin Gönderimi İçin Maksimum Token Boyutu Nedir?
Google algoritmasında devasa projelerinizde sorun yaşamamanız için, API hattına tek bir istek paketinde tam anlamıyla 8.192 adede kadar maksimum giriş belirtecini (token) rahatça iletmenize sorunsuzca izin verilir. Bu uzun formlar için harika bir yaklaşımdır.
Projemi Eski Sürümden Yeni Mimarisine Geçirirken Verilerimi Silmem Gerekir Mi?
Bu işlem zorunludur çünkü iki farklı modelin veri gömme (embedding) anlamsal alanları uzayda birbirinden tamamen farklı noktalardadır ve geriye dönük uzlaştırma yapamazlar. Tüm verilerinizi silmeniz, API'den yepyeni bağlantılar çağırarak yepyeni bir eşleme çalışması koşturmanız kesinlikle gerekir.
Türkçe Yazılım Projelerinde Gemini Entegrasyonunun Performansı Nasıldır?
Çıktılara göre proje tam 100'den fazla benzersiz dilde genel MTEB istatistik skorlamalarında en üst rakip konumundadır. Açık kaynak kodlarına sahip diğer muadil yerel Türkçe geliştirilmiş BERT modellerini açık ara skorlarla çok gerilerde bırakan güçlü bir potansiyele ve test edilen ortamlarda yüzde doksan dokuzdan yüksek (%99+) doğru sınıflandırma oranına imza atmayı harika şekilde başarmıştır.